Introduction
This is a summary of a recent video from NVIDIA’s Dynamo Day in January, covering two main topics: PD-disaggregated inference in 2025 and the future trends of AI inference in 2026.
The Main Thread of Inference in 2025: PD Disaggregation
Currently, LLM inference faces two key challenges: throughput and latency.
Latency is typically measured by two finer metrics: Time to First Token (TTFT) and Time per Output Token (TPOT).
Both should be as low as possible, so that after entering a prompt, the user receives a response immediately.
In my personal opinion, LLM inference also has a cost issue.
“You can have it all” is not impossible—it’s just that users aren’t willing to pay that much.
Therefore, different applications can have different Service Level Objectives (SLOs). For example, for something like ChatGPT, TTFT needs to be very fast, but TPOT can be a bit slower; for paper summarization, TTFT can be a bit slower, but TPOT should be faster.
However, high throughput does not equal high goodput.
High Throughput != High Goodput
As shown in the figure, processing 10 requests per second counts as high throughput, but only 3 of them meet the TTFT and TPOT requirements, so the number of effective requests is very low.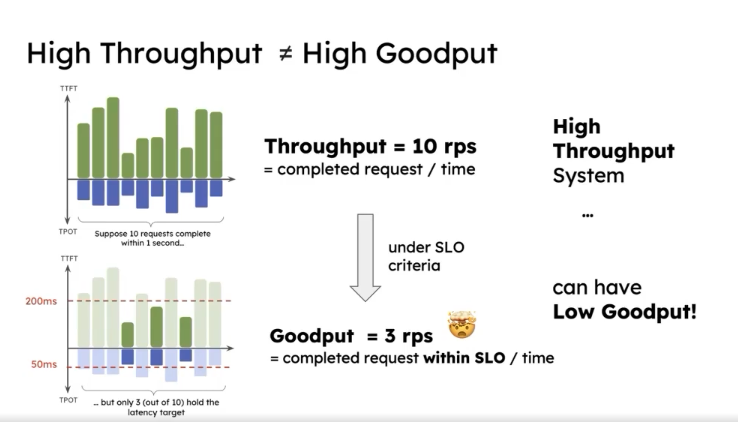
A major trend in 2025 is PD (prefill/decode) disaggregation. Prefill and decode are executed on different GPUs: the prefill worker processes requests first, then transfers data to the decode worker for processing.
Continuous Batching
Before PD disaggregation, the best technique available was continuous batching, but it introduces interference between the prefill and decode phases.
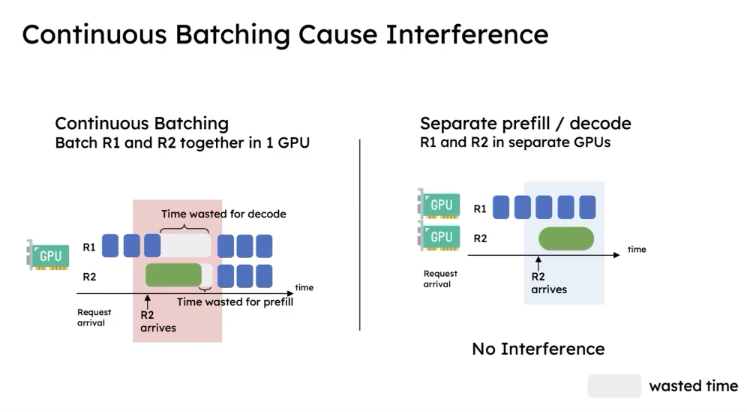
Let me explain what this image means: the left side shows traditional continuous batching, and the right side shows PD disaggregation. The blue bars represent the decode phase, and the green bars represent the prefill phase. On the left, while R1 is executing decode, it receives a request from R2. To batch the data together, R1 must stop and wait for R2 to finish its prefill before they can decode together. This process causes the resource waste shown as the white rectangles in the diagram. After PD disaggregation, this problem no longer exists because there are two separate GPUs.
Figure 3 illustrates one thing: as long as you have enough money, achieving both low TTFT and low TPOT (“have it all”) is possible.
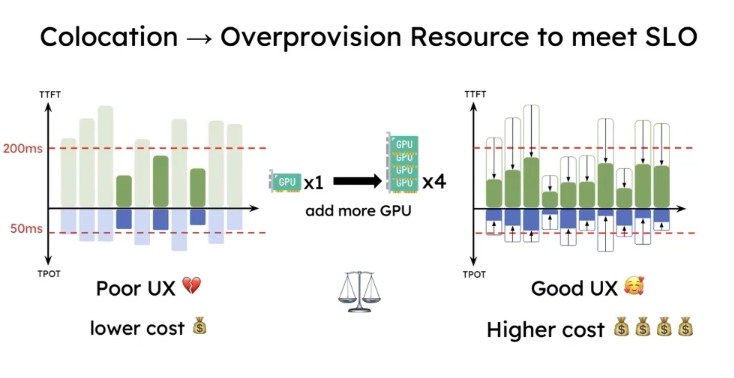
Opportunity: PD Disaggregation
- Eliminates interference between the prefill and decode phases.
- Naturally splits the SLO objectives into two optimization directions: prefill optimizes TTFT, and decode optimizes TPOT. Choose the appropriate resources and parallelism strategy.
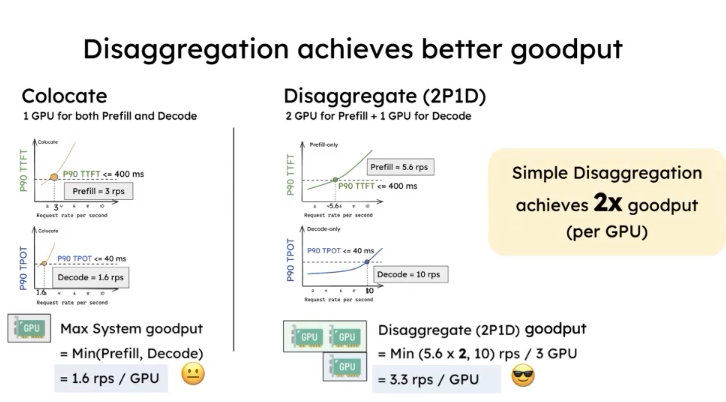
After PD disaggregation, GPU utilization per card can double. Originally with one card, it handled 1.6 requests per second per card; now with two cards, each card handles 3.3 requests per second.
Core Problem: XPYD
p1-placement: Given workload demands, solve X and Y to maximize GPU goodput.
p2-communication: Minimize the KV Cache communication cost between XP and YD.
Some notable disaggregated inference systems: LMCache / HiCache / Dynamo / Cachegen / DeepSeek-V3
Trends in AI Inference for 2026
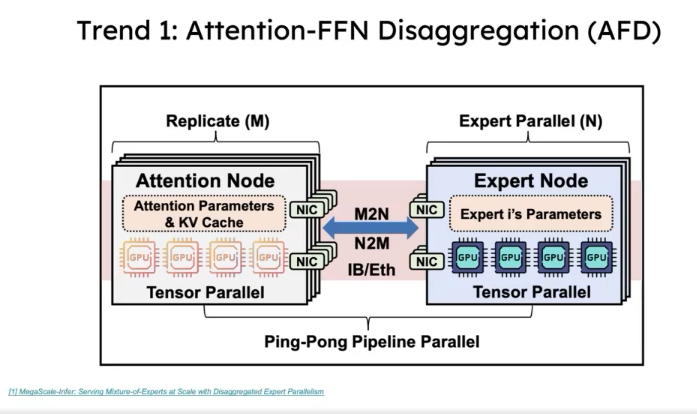
- Attention-FFN disaggregation
- Traffic for diffusion models is growing rapidly
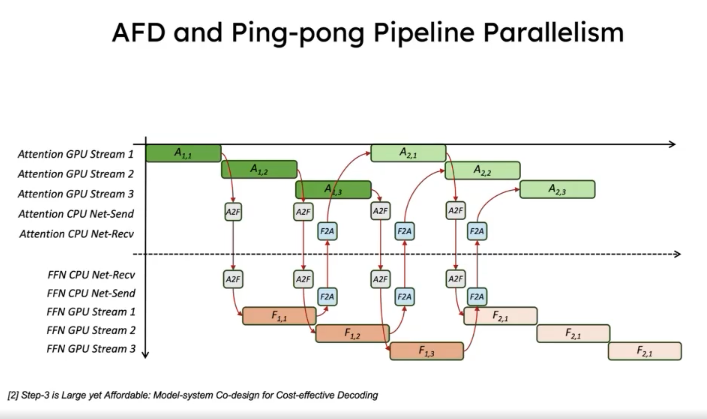
These two topics are quite ahead of their time—I didn’t fully understand them. I’ll include two images to give you a sense: the idea is to break the original execution pipeline into smaller chunks and execute them in a CPU-pipeline-like fashion, which can achieve some speedup.
On the diffusion model side, the main focus is video generation. Currently, the cost of generating videos is very high for most companies. The speaker’s own team has open-sourced a project called FastVideo, which seems to be attempting to address related issues. Those interested can take a look.